Compression is often avoided in memory-resident OLTP databases since it reduces transaction processing throughput. Hence today’s paper: Compacting Transactional Data in Hybrid OLTP & OLAP Databases authored by Florian Funke, Alfons kemper and Thomas Neumann. In it, the authors' goal is to demonstrate that compression can indeed be utilized in an OLTP database in a lightweight manner that doesn’t significantly impact ‘mission-critical’ transaction throughput. They do this by leveraging hardware to track which tuples are hot and which ones are cold thereby leaving OLTP threads to only handle query processing. Once cold tuples have been identified, they can be compressed thus availing more memory for newer entries and also for query execution. It’s worth noting that their solution doesn’t strictly fall into the ’larger-than-memory’ category since it’s assumed that all the data remains in memory; rather, they want to leverage the hot/cold skew observed in ‘real-world’ data so as to pack more tuples in memory.
Here’s the overview of their solution which is implemented in HyPer, a hybrid database that handles both OLTP and OLAP workloads:
Data Organization #
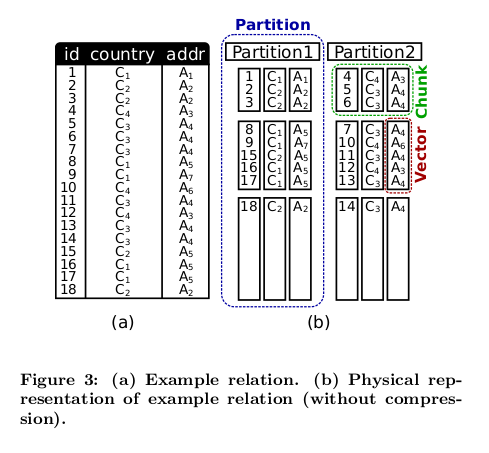
Let’s consider a relation (table) that consists of the following attributes
id, country and addr. In HyPer, such relation is split into several
partitions. Within partitions, tuples are stored in a columnar format rather
than in a row-oriented format. Therefore, each attribute is stored in its own
column. The columns are then split further into separate vectors rather than
have them all stored in a single contiguous block. This is key since it allows
each vector to be stored in different types of memory pages and be categorized
and compressed differently depending on its status (hot, cold). Vectors
comprising the same group of tuples then form a chunk.
Figure 3 from [1]
Clustering Tuples into Hot & Cold #
I’ve already highlighted in previous posts the whole utility of hot/cold categorization plus how it arises from the tendency of data access in OLTP being skewed; in the interest of time, I won’t go over it again here.
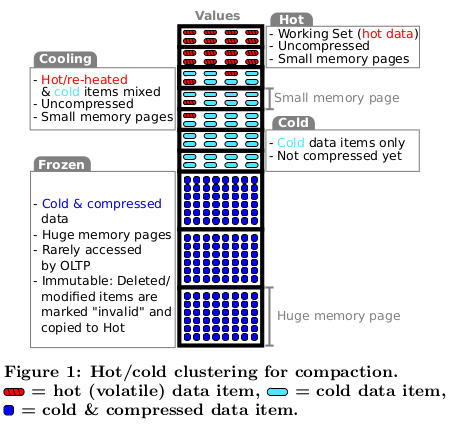
The only major difference worth noting is that in HyPer is that the hot/cold classification is carried out across chunks and vectors (portions of columns) rather than on individual rows/tuples. Additionally, there are 4 categories representing the ’temperature’ instead of just 2:
- Hot: “Entries in a hot vector are frequently read/updated or tuples are deleted and/or inserted into this chunk”. All inserts go into hot chunks. Updates and deletes are in-place.
- Cooling: “Most entries remain untouched, very few are being accessed or tuples are being deleted in this chunk”. Accessing a tuple that’s in a cooling chunk triggers its relocation into a hot chunk. However, deletes are carried out in-place.
- Cold: These are vectors which have not been accessed by OLTP queries for a given period.
- Frozen: These are cold vectors that get organized and compressed physically into an immutable format that is optimized for OLAP queries.
In both cold and frozen chunks, updates and deletes are not carried out in-place. If a cold/frozen tuple is modified, it is copied back into the hot section before applying the modification. Separately, there’s a mutable structure that indicates that the tuple’s old data in the cold/frozen section is ‘invalid’. Table scans of cold & frozen tuples therefore have to check the validity status of tuples before handing them over to upstream operators.
Figure 1 from [1]
In previous posts, we’ve seen LRU & other caching algorithms being used to identify and track hot tuples. HyPer’s approach is quite different given that they’re tracking hotness/coldness at the granularity of a page rather than individual tuples. Here’s how they do it:
Access Observer #
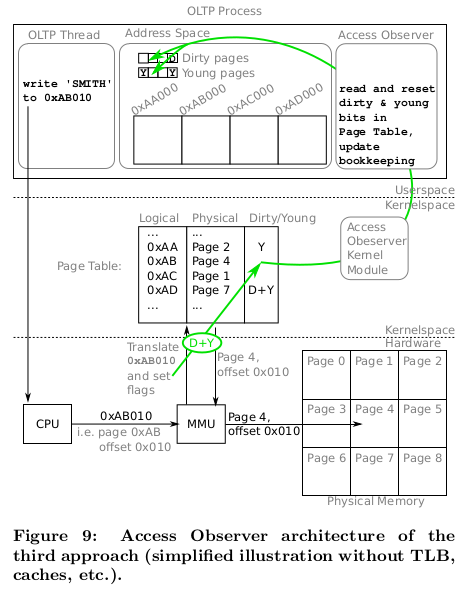
HyPer contains a separate component, the Access Observer, which “monitors reads and writes performed by OLTP threads in order to determine which parts of the database are cold and which ones are hot”.
In contrast with other approaches that I’ve highlighted in previous posts, the
Access Observer is hardware assisted rather than being purely software-based.
Whenever a memory page is read or written to, the MMU (hardware) sets its
young/accessed bit. Also, if it was a write, the MMU also sets the page’s
associated dirty bit. The accessed bit and the dirty bit are meant to be used by
the OS to manage memory across various processes such as by evicting LRU virtual
pages so that the underlying physical page can be availed to other workloads.
HyPer’s novel idea (at least to me) is running the Access Observer as a kernel
module so that the database system can get access to the pages’ metadata and use
it to determine which chunks are still hot and which ones are getting cooler and
thus are suitable candidates for compaction. The Access Observer also takes
charge of resetting the physical pages metadata by mlock-ing the pages its
tracking so that the OS can’t reset the metadata during swapping.
Figure 9 from [1]
Compacting Cold Data #
Once cold chunks have been identified, they are earmarked for compaction i.e. ‘freezing’. Compacting involves compression and data reorganization.
With compression, the authors note that the goal of their paper isn’t to develop nor explore new approaches but rather to take what already works and utilize it prudently while minimizing the impact on transaction processing as much as possible. Consequently, they opt dictionary compression and further apply run-length encoding (RLE) in cases where it’s beneficial (e.g. when there’s lots of null values). This approach is not only quite effective in compressing most kinds of data, it also speeds up OLAP query processing in lots of cases.
As for reorganization, frozen pages are stored into so-called huge virtual memory pages (2MB vs 4KB for normal pages in x86) and also made immutable. This brings with it the following advantages:
- Fewer TLB misses resulting in faster scans
- Reduction in TLB thrashing since OLAP queries and OLTP queries utilize different sections of the TLB (huge pages vs small pages respectively)
- Faster snapshotting: OLAP queries are ran in a forked process that inherits a snapshot of the parent’s page table. Use of huge pages means the page table is smaller hence making copies of it becomes faster
Conclusion #
As with any academic paper worth its salt, the authors carry out various evaluations to justify and verify their methodology. It would be interesting to revisit HyPer’s compression strategy given that there are newer approaches to DB-optimized compression (see Lightweight Compression in DuckDB). Also, at some point a user might run out of physical memory and vertical scaling might not be an option: therefore, I would have loved to see how much implementing the transfer of cold data to SSD/Disk would impacts the design of rest of the system though the authors state that such an undertaking is beyond the scope of the paper. Overall, the paper definitely is worth checking out.