Egor Rogov (author of one of my favourite book, PostgreSQL Internals) wrote this illustrative article, On recursive queries that’s worth reading for SQL aficionados. The dataset used is the airlines demo database - it consists of airports, flights available between these airports and other details such as planes used and flight durations. The article concludes with a couple of intermediate/advanced exercises that involve using SQL to solve some variation of finding paths or routes between locations (nodes) that fulfill some condition or constraint e.g. minimum number of airport hops or least waiting time.
Now, I did have fun working through the exercises. However, I’m curious if Graph Databases could simplify modeling and solving such tasks. The aspect I’m focusing on is the interface - that is, to quote Larry Wall, for these kinds of problems I’m hoping Graph DBs to “make the easy things easy and the hard things possible”.
I’d also like to note, this isn’t a proper rigorous comparison or study, I’m just expecting that as a novice in graph databases, I should not break much of a sweat. If I’m spending too much time and finding it too complicated to formulate the equivalent graph queries, then maybe the interface aspect is oversold (if to no one else then at least to me).
By interface I mean the ‘UI/UX’ with regards to data modeling and data querying. For modeling, I find the relational approach quite neat. In my career thus far, I’ve yet to come across a business case that couldn’t be modeled relationally and, (maybe I’m in a bubble here), I’ve yet to meet anyone (including myself) complain about being limited or inconvenienced by the relational model. As for querying, SQL isn’t quite everyone’s cup of tea (see Against SQL for a decent overview of SQL’s shortcomings). Sure, there are newer query languages and extensions that are meant to address SQL’s deficiency but for the time being, we’re pretty much stuck with it. I won’t complain much about SQL as an interface probably because I’ve gotten used to it.
I’ll be using DuckDB as the representative relational DB and KuzuDB as the representative Graph DB. Both are serverless plus I’m a big fan of DuckDB’s SQL dialect (which is derived from Postgres’s). Also it doesn’t hurt that KuzuDB integrates directly with DuckDB which means I don’t have to do a separate ETL/ELT.
Let’s start with an overview of the database. Here’s the high-level schema:
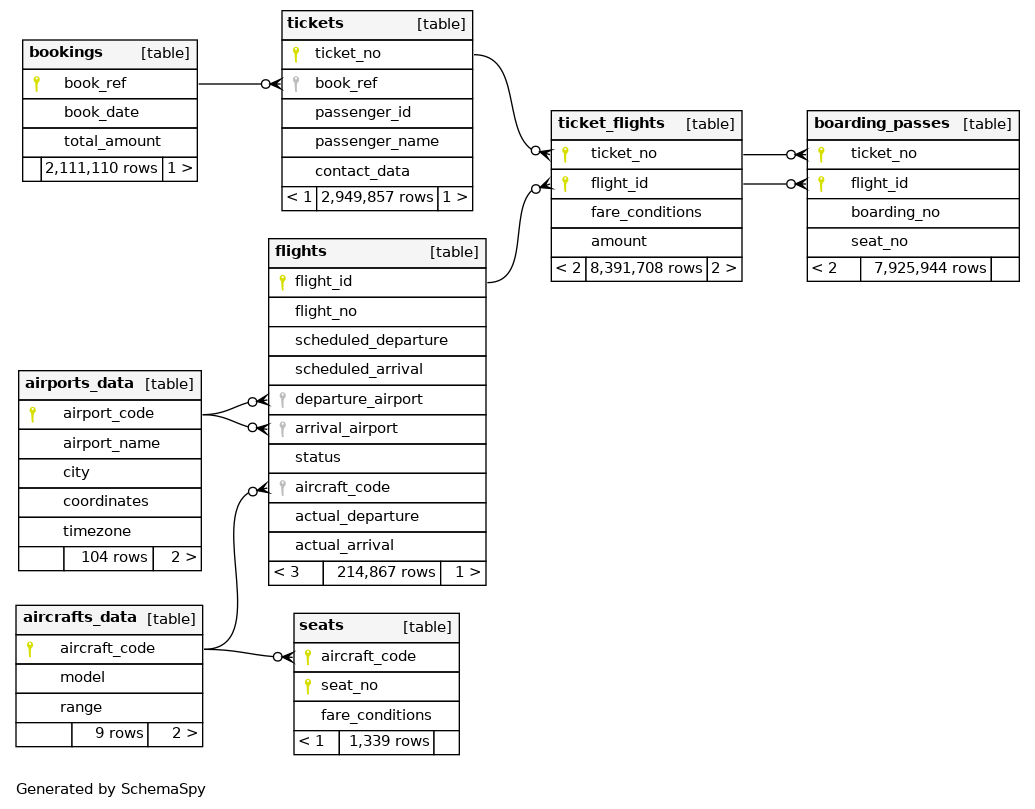
A flight between two airports is scheduled to start at a certain time for some
or all days of the week plus take some expected amount of time and use the
assigned aircraft. Given that it’s periodic, it’s assigned a unique ID
flight_no. The flights table records all flights, those that already took
place, the ones currently taking place (at the time the dataset was being
collected), any flight that was canceled and even future scheduled flights.
To simplify analysis, we’ll focus on distinct flights (by flight_no)
regardless of how many times that flight appears in the flights table. Hence
the routes view which lists all the distinct flights, plus we’ve got the
departure point, arrival point, how long the flight is expected to take, and
which days of the week the flight is offered.
The routes view is defined as follows:
create or replace view routes as
with t as (
select
flight_no,
list_sort(list_distinct(array_agg(weekday(scheduled_departure)))) as days_of_week
from flights
group by flight_no
)
select distinct on(flight_no)
f.flight_no,
f.departure_airport,
d.airport_name as departure_airport_name,
d.city as departure_airport,
f.arrival_airport,
a.airport_name as arrival_airport_name,
a.city as arrival_city,
f.aircraft_code,
(f.scheduled_arrival - f.scheduled_departure) as duration,
t.days_of_week
from flights f
join t using(flight_no)
join airports d on f.departure_airport = d.airport_code
join airports a on f.arrival_airport = a.airport_code
And here’s the schema for the routes view:
View "bookings.routes"
Column │ Type
════════════════════════╪══════════════
flight_no │ varchar
departure_airport │ varchar
departure_airport_name │ varchar
departure_city │ varchar
arrival_airport │ varchar
arrival_airport_name │ varchar
arrival_city │ varchar
aircraft_code │ varchar
duration │ interval
days_of_week │ int64[]
Now, suppose we want to search for the shortest route that starts from Ust-Kut airport (UKX) and ends at Chulman Airport in Neryungri (CNN). Here’s how to do it in SQL:
-- shortest route from UKX to CNN
set variable starting_point = 'UKX';
set variable destination = 'CNN';
with recursive p(hops, flights, curr_airport, found) as (
select
[getvariable('starting_point')], -- hops
[]::varchar[], -- flights taken
getvariable('starting_point'),
getvariable('starting_point') = next.airport_code -- found?
from airports next
where next.airport_code = getvariable('destination')
union all
select
list_append(p.hops, r.arrival_airport),
list_append(p.flights, r.flight_no),
r.arrival_airport, -- curr airport
bool_or(r.arrival_airport = getvariable('destination')) over()
from routes r, p
where r.departure_airport = p.curr_airport
and not r.arrival_airport = any(p.hops)
and not p.found
)
select hops, flights
from p
where p.curr_airport = getvariable('destination')
Egor explains how the above query works and one might go about formulating it so do check out his post if you’re interested.
Running it we get the following result:
┌───────────────────────────┬──────────────────────────────────┐
│ hops │ flights │
│ varchar[] │ varchar[] │
├───────────────────────────┼──────────────────────────────────┤
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0207, PG0390, PG0036] │
│ [UKX, KJA, OVB, PEE, CNN] │ [PG0022, PG0207, PG0186, PG0394] │
│ [UKX, KJA, BAX, ASF, CNN] │ [PG0022, PG0653, PG0595, PG0427] │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0206, PG0390, PG0036] │
│ [UKX, KJA, OVB, PEE, CNN] │ [PG0022, PG0206, PG0186, PG0394] │
│ [UKX, KJA, SVO, ASF, CNN] │ [PG0022, PG0548, PG0128, PG0427] │
│ [UKX, KJA, SVO, MJZ, CNN] │ [PG0022, PG0548, PG0120, PG0036] │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0207, PG0390, PG0035] │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0206, PG0390, PG0035] │
│ [UKX, KJA, SVO, MJZ, CNN] │ [PG0022, PG0548, PG0120, PG0035] │
│ [UKX, KJA, SVO, LED, CNN] │ [PG0022, PG0548, PG0470, PG0245] │
│ [UKX, KJA, SVO, LED, CNN] │ [PG0022, PG0548, PG0469, PG0245] │
│ [UKX, KJA, SVO, LED, CNN] │ [PG0022, PG0548, PG0471, PG0245] │
│ [UKX, KJA, OVS, LED, CNN] │ [PG0022, PG0689, PG0686, PG0245] │
│ [UKX, KJA, SVO, LED, CNN] │ [PG0022, PG0548, PG0472, PG0245] │
│ [UKX, KJA, SVO, LED, CNN] │ [PG0022, PG0548, PG0468, PG0245] │
│ [UKX, KJA, NUX, DME, CNN] │ [PG0022, PG0623, PG0165, PG0709] │
│ [UKX, KJA, BAX, DME, CNN] │ [PG0022, PG0653, PG0117, PG0709] │
│ [UKX, KJA, OVB, DME, CNN] │ [PG0022, PG0207, PG0223, PG0709] │
│ [UKX, KJA, OVB, DME, CNN] │ [PG0022, PG0206, PG0223, PG0709] │
│ [UKX, KJA, OVS, DME, CNN] │ [PG0022, PG0689, PG0543, PG0709] │
│ [UKX, KJA, KRO, DME, CNN] │ [PG0022, PG0673, PG0371, PG0709] │
│ [UKX, KJA, OVS, DME, CNN] │ [PG0022, PG0689, PG0544, PG0709] │
├───────────────────────────┴──────────────────────────────────┤
│ 23 rows 2 columns │
└──────────────────────────────────────────────────────────────┘
Let’s see how we can accomplish the same in the Graph DB counterpart. First, the schema:
CREATE NODE TABLE Airport(
airport_code STRING,
name STRING,
city STRING,
PRIMARY KEY (airport_code)
);
CREATE REL TABLE Route(
FROM Airport TO Airport,
flight_no STRING,
aircraft_code STRING,
duration INTERVAL,
days_of_week INT64[]
)
Now for the query (shortest route from UKX to CNN based on number of hops from one airport to the next):
MATCH p=(a:Airport)-[:Route* ALL SHORTEST]->(b:Airport)
WHERE a.airport_code = 'UKX'
AND b.airport_code = 'CNN'
RETURN
properties(nodes(p), 'airport_code') as hops,
properties(rels(p), 'flight_no') as flights
So far so good. It seems both elegant and succinct, definitely not as hairy as the SQL variant.
Also, just to make sure we’re getting the same results, we can take advantage of
both Kuzu and DuckDB’s arrow export feature plus the except clause in SQL:
duckdb_conn.register("A", kuzu_res)
duckdb_conn.register("B", duckdb_res)
tables_match = duckdb_conn.sql(
"""
select
(count(*) == 0)
and
(select count(*) from A) == (select count(*) from B)
as tables_match
from (
select hops,flights from A except all
select hops,flights from B
)
"""
).fetchone()
assert tables_match[0] == True
What if we’re interested in the route where we’ll spend the least amount of time in air (ignoring the time we’ll spend in airports while we wait for the connection flights). With SQL, we can extend the first query which results in the following solution:
set variable starting_point = 'UKX';
set variable destination = 'CNN';
with recursive p(hops, flights, curr_airport, total_duration, found) as (
select
[getvariable('starting_point')], -- airports we've been at, so far the start only
[]::varchar[], -- flights taken, so far none
getvariable('starting_point'),
'0 minutes'::interval, -- we've spent 0 minutes flying so far
getvariable('starting_point') = next.airport_code -- reached destination ?
from airports next
where next.airport_code = getvariable('destination')
union all
select
list_append(p.hops, r.arrival_airport),
list_append(p.flights, r.flight_no),
r.arrival_airport, -- curr airport
total_duration + r.duration,
bool_or(r.arrival_airport = getvariable('destination')) over()
from routes r, p
where r.departure_airport = p.curr_airport
and not r.arrival_airport = any(p.hops)
and not p.found
)
select * exclude r from (
select
hops, flights, total_duration,
rank() over(order by total_duration asc) as r
from p
where p.curr_airport = getvariable('destination')
)
where r = 1
This gives us the following results:
┌───────────────────────────┬──────────────────────────────────┬────────────────┐
│ hops │ flights │ total_duration │
│ varchar[] │ varchar[] │ interval │
├───────────────────────────┼──────────────────────────────────┼────────────────┤
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0207, PG0390, PG0036] │ 10:25:00 │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0206, PG0390, PG0036] │ 10:25:00 │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0207, PG0390, PG0035] │ 10:25:00 │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0206, PG0390, PG0035] │ 10:25:00 │
└───────────────────────────┴──────────────────────────────────┴────────────────┘
With Kuzu, we’ll have to recast the flight durations as integers (minutes) since it doesn’t support summing intervals, yet. The equivalent query I ended up with is as follows:
MATCH p=
(a:Airport {airport_code: 'UKX'})-[:Route* ALL SHORTEST]->(b:Airport {airport_code: 'CNN'})
WITH min(list_sum(properties(rels(p), 'duration'))) as min_duration
MATCH p=
(a:Airport {airport_code: 'UKX'})-[:Route* ALL SHORTEST]->(b:Airport {airport_code: 'CNN'})
WITH p as p, min_duration as min_duration, list_sum(properties(rels(p), 'duration')) as d
WHERE d = min_duration
RETURN
properties(nodes(p), 'airport_code') as hops,
properties(rels(p), 'flight_no') as flights,
to_minutes(d) as total_duration
There might be some better way of writing it but this is what I was able to come
up with after an evening of studying cypher. The with clause lets us break the
query into steps.
In the first part, we get the minimum duration amongst all paths from UKX to CNN:
MATCH p=
(a:Airport {airport_code: 'UKX'})-[:Route* ALL SHORTEST]->(b:Airport {airport_code: 'CNN'})
WITH min(list_sum(properties(rels(p), 'duration'))) as min_duration
Then in the second part, we get all the paths that have this exact minimum duration:
MATCH p=
(a:Airport {airport_code: 'UKX'})-[:Route* ALL SHORTEST]->(b:Airport {airport_code: 'CNN'})
WITH p as p, min_duration as min_duration, list_sum(properties(rels(p), 'duration')) as d
WHERE d = min_duration
RETURN
properties(nodes(p), 'airport_code') as hops,
properties(rels(p), 'flight_no') as flights,
to_minutes(d) as total_duration
The with clause was a bit hard for me to wrap my head around; in my opinion
CTEs and explicit sub-queries seem more approachable. Kuzu DB’s Cypher does have
subqueries but they are rather limited in terms of where they can be placed and
used. Regardless, I was able to get the job done.
As an aside, given that both Kuzu and DuckDB speak arrow, we could use the Kuzu to get all the paths, then use DuckDB to pick the shortest path:
import kuzu
import duckdb
db = kuzu.Database("flights")
kuzu_conn = kuzu.Connection(db)
routes_tbl = kuzu_conn.execute(
"""
MATCH p=
(a:Airport {airport_code: 'UKX'})-[:Route* ALL SHORTEST]->(b:Airport {airport_code: 'CNN'})
RETURN
properties(nodes(p), 'airport_code') as hops,
properties(rels(p), 'flight_no') as flights,
to_minutes(list_sum(properties(rels(p), 'duration'))) as total_duration
"""
).get_as_arrow()
duckdb.sql(
"""
select * exclude r from (
select
hops,
flights,
total_duration,
rank() over(order by total_duration asc) as r
from routes_tbl
) where r = 1
"""
).show()
For the final exercise, a query we might find useful in ‘real-life’: given two airports UKX and CNN and the specific time when we want to commence our journey, we’d like to find the path of flights where we’ll spend the least amount of time including the waits for connection flights. To make it slightly harder (and more realistic), there’s a temporal aspect, we have a specific time when we’ll be starting the journey. Therefore, at each hop, we have to pick the soonest/closest/earliest flights to avoid spending too much time at the airport.
Solving it in SQL is a bit more challenging but I was able to get the job done. Here’s my solution:
-- starting point and ending point, set by user
set variable starting_point = 'UKX';
set variable destination = 'CNN';
-- point in time dataset was generated
set variable now = '2017-08-15 18:00:00'::timestamp at time zone 'Europe/Moscow';
-- time from which onwards we're ready for departure
set variable starting_time = getvariable('now') - '20 days'::interval;
with recursive
p(hops, flights, curr_airport, time_user_arrived_at_curr_airport, total_duration, closest, found)
as (
select * from (
select
[departure_airport, arrival_airport]::varchar[] as hops,
[flight_no]::varchar[] as flights,
arrival_airport as curr_airport, -- where we are
scheduled_arrival as time_user_arrived_at_curr_airport,
(scheduled_arrival - scheduled_departure) as total_duration,
rank() over(
partition by flight_no, departure_airport, arrival_airport
order by scheduled_departure asc
) as closest,
arrival_airport = getvariable('destination') as found
from flights
where
departure_airport = getvariable('starting_point')
and scheduled_departure >= (getvariable('now') - '20 days'::interval)
) where closest = 1
union all
select * from (
select
list_append(p.hops, f.arrival_airport) as hops,
list_append(p.flights, f.flight_no) as flights,
f.arrival_airport as curr_airport,
f.scheduled_arrival as arrived_at_time,
p.total_duration
-- duration user will spend flying to next airport
+ (f.scheduled_arrival - f.scheduled_departure)
-- duration user will wait before departure
+ (f.scheduled_departure - p.time_user_arrived_at_curr_airport),
rank() over(
partition by flight_no, departure_airport, arrival_airport
order by scheduled_departure asc
) as closest,
bool_or(f.arrival_airport = getvariable('destination')) over()
from flights f
inner join p on f.departure_airport = p.curr_airport
where
f.scheduled_departure >= p.time_user_arrived_at_curr_airport
and not f.arrival_airport = any(p.hops) -- no cycles
and not p.found -- have we arrived at destiation yet?
) where closest = 1
)
select * exclude r from (
select
hops, flights, total_duration,
rank() over(order by total_duration asc) as r
from p
where p.curr_airport = getvariable('destination')
)
where r = 1
order by flights
It gives us the following routes:
┌───────────────────────────┬──────────────────────────────────┬────────────────┐
│ hops │ flights │ total_duration │
│ varchar[] │ varchar[] │ interval │
├───────────────────────────┼──────────────────────────────────┼────────────────┤
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0206, PG0390, PG0035] │ 70:55:00 │
│ [UKX, KJA, OVB, MJZ, CNN] │ [PG0022, PG0207, PG0390, PG0035] │ 70:55:00 │
│ [UKX, KJA, SVO, MJZ, CNN] │ [PG0022, PG0548, PG0120, PG0035] │ 70:55:00 │
└───────────────────────────┴──────────────────────────────────┴────────────────┘
Now with Cypher, I would have to add a new kind of edge for individual flights rather than general route:
CREATE REL TABLE Flight(
FROM Airport TO Airport,
flight_id INT64,
flight_no STRING,
aircraft_code STRING,
scheduled_departure TIMESTAMP,
scheduled_arrival TIMESTAMP,
status STRING,
actual_departure TIMESTAMP,
actual_arrival TIMESTAMP
)
However, I was unable to formulate a solution in Cypher. If you can do it, please reach out, I’d love to learn how.
Overall, Cypher seems neat. For simple graph queries, it offers a better interface than SQL. For more complex queries, SQL has a wider array of tools that one can use when tackling them. I’ll be spending as much time as possible with Graph DBs so I can understand better what they’re great at and what I can accomplish with them. Cheers.