First thing’s first, lateral joins are not quite a different type of joins - it’s a way for sneaking in for-loops into SQL. With that in mind, let’s use a rather contrived example to introduce lateral joins.
Suppose we’re running a social music streaming app. Users can follow each other plus, of course, stream songs. We want to add the following feature (let me phrase it in Jira speak): ‘as a user, I want to get the top 5 songs the people I follow have been listening to in the past 1 week, that I haven’t listened to yet - so that I can, uhh, listen to them?’
Data definition #
Let’s first flesh out the tables, nothing too fancy:
create table users(
user_id int primary key,
name varchar not null,
joined_on date
);
create table follow_list(
user_id int references users(user_id) on delete cascade,
followed_by int references users(user_id) on delete cascade,
primary key(user_id, followed_by),
check (user_id <> followed_by) -- user can't follow themselves
);
create table songs(
song_id int primary key,
name varchar not null,
artist varchar not null
);
create table song_plays(
user_id int not null references users(user_id),
song_id int not null references songs(song_id),
ts timestamptz not null default now()
);
insert into users values
(1, 'Alice'),
(2, 'Bob'),
(3, 'Eve');
Every time a user plays a song, it’s recorded in the song_plays, ts is the
time they played it.
Building block queries #
Let’s start by getting everyone Alice follows:
select
user_id,
name
from (
select
user_id,
name
from follow_list
join users using(user_id)
where followed_by = 1
) as follows
Bob is one of the users Alice follows. This is how we get his top 5 most played songs in the past week:
select
song_id,
count(*) as num_plays
from song_plays
where
user_id = 2
and ts > now() - '1 week'::interval
group by song_id
order by num_plays desc
limit 5;
We also have to keep track of the songs Alice has already played:
select
distinct song_id
from song_plays
where user_id = 1;
Client side querying and iteration #
Let’s now bring in everything together for version 1 of the feature:
alice_id = 1
alice_playlist = []
with conn.cursor() as cur:
# get already played songs to filter out
sql = """
select distinct song_id
from song_plays
where user_id = %s;
"""
cur.execute(sql, (alice_id,))
res = cur.fetchall()
already_played = tuple(song_id for row in res for song_id in row)
# get followees
sql = """
select
user_id,
name
from follow_list f
join users using(user_Id)
where followed_by = %s
"""
cur.execute(sql, (alice_id,))
follows = cur.fetchall()
print(follows)
# for each followee, get their top-5 most played songs in the past
# week, filter out songs the user has already played
sql = """
select
%s
name,
artist,
num_plays
from songs
join (
select
song_id,
count(*) as num_plays
from song_plays
join songs using(song_id)
where
user_id = %s
and ts > now() - '1 week'::interval
and song_id not in %s
group by song_id
order by num_plays desc
limit 5
) as top_songs using(song_id)
"""
for (followee_id, followee_name) in follows:
cur.execute(sql, (followee_name, followee_id, already_played))
alice_playlist.extend(cur.fetchall())
# print Alice's generated playlist playlist
for entry in alice_playlist:
print(entry)
The one thing that sticks out like a sore thumb is that there is a lot of back and forth querying between the client and the database for stuff that could be handled entirely within Postgres in one sweep. This increases the latency and amount of unnecessary workload. Let’s fix it.
Set returning functions #
As the first step towards keeping as much of the workload within Postgres, let’s create a function which given a user and someone they follow, returns the top 5 songs the followee listened to in the past week. It should also filter out songs the user has already listened to. For this, we’ll use set-returning functions.
Dimitri Fontaine, author of ‘The Art of Postgres’, defines a set returning function as:
a PostgreSQL Stored Procedure that can be used as a relation: from a single call it returns an entire result set, much like a subquery or a table - Set Returning Functions and PostgreSQL 10
This section
of the Postgres documentation introduce set returning functions quite well.
Probably the most well-known set returning function is generate_series.
For our case, this will do:
create function top_songs(u_id integer, followee_id integer)
returns table(song_id int, num_plays int)
as $$
select
song_id,
count(*) as num_plays
from song_plays
where
user_id = followee_id
and ts > now() - '1 week'::interval
and song_id not in (
select distinct song_id from song_plays where user_id=u_id
)
group by song_id
order by num_plays desc
limit 5;
$$ language sql;
Wiring it up to the overall query:
select
followee_name,
s.name,
s.artist,
t.num_plays
from (
select
user_id as followee_id,
name as followee_name,
followed_by as user_id
from follow_list f
join users using(user_id)
where followed_by = 1
) as f,
top_songs(user_id, followee_id) as t
join songs as s using(song_id)
order by f.followee_id asc, t.num_plays desc;
Two rather implicit things to note in the above query:
- the comma in between the subquery
fandtop_songsresults in a cross join: this is a kind of join where each row in the left table is matched with all rows in the right table - resulting in all possible combinations. I’d say it’s the building block for all other kinds of joins but that’s a post for another day. - we’ve just used a lateral join; it’s time to formally introduce the
lateral keyword
Lateral Joins #
Once more, lateral joins aren’t a kind of join (unlike inner joins, left joins
etc). Rather, lateral is a keyword that when appended before a subquery or
function in the from section, let’s it ‘access’ the columns from the prior
table expressions.
Let’s wind back a bit and revisit the order of SQL queries: We start with from
then joins then the where clause and so on:
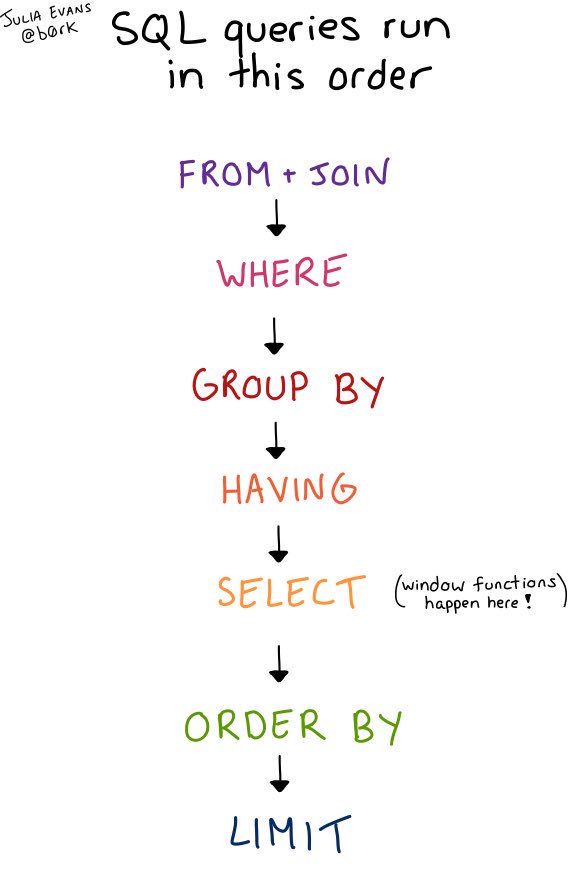
The image above is from Julia Evans’ blog post SQL queries don’t start with SELECT, all credits due.
Loosely speaking, before a subquery is joined with another table, it is evaluated once fully into a single table.
However, in our case, we have to generate the top songs on the fly for everyone
a user follows. This necessitates some form of row-by-row iteration - hence the
need for the lateral keyword. With lateral, the subquery or function is
evaluated iteratively for every row in from the prior result set. The
subquery/function can also reference columns from the prior result set such as
in a where clause to filter out songs a user has already listened to. The rows
from the subquery/function are then ‘combined’ back, since it’s a join after
all.
We didn’t use the lateral keyword for the top_songs function even though it
refers to the user_id and followee_id columns since Postgres makes it
optional.
However, for subqueries, we have to use lateral. Let’s also make the cross
join explicit and track the songs already played using a
Common Table Expression.
with already_played as (
select distinct song_id
from song_plays
where user_id = 1
)
select
followee_name,
songs.name,
songs.artist,
top_songs.num_plays
from (
select
user_id as followee_id,
name as followee_name
from follow_list
join users using(user_id)
where followed_by = 1
) as f
cross join lateral (
select
song_id,
count(*) as num_plays
from song_plays
where
user_id = f.followee_id
and ts > now() - '1 week'::interval
and song_id not in (select song_id from already_played)
group by song_id
order by num_plays desc
limit 5
) as top_songs
join songs using(song_id)
order by followee_id asc, num_plays desc
With this query, we get the entire result within a single round-trip, no more
back and forth. And by using lateral with a subquery, we don’t have to create
and maintain a function within Postgres, everything’s right there within the
query. Note, when subqueries are used in the above manner, they are referred to
as correlated subqueries. From
wikipedia, a correlated
subquery is a ‘subquery that uses values from the outer query’
Simplifying/Reusing expressions #
Additionally, the lateral keyword can also use it to simplify queries as highlighted in both Vlad Mihalcea’s Stack Overflow answer and this PopSQL post that introduces Lateral Joins. I’ll heavily borrow Mihalcea’s example:
In our users table above, we were also keeping track of the day the users
created an account via the joined_on column. Suppose we want to send out some
offers to users based on:
- how many years they’ve been members
- the date of their next anniversary
- the number of days remaining until their next anniversary
This query does the trick:
select
user_id,
name,
joined_on,
extract (year from age(now(), joined_on)) as years_active,
(joined_on +
(extract(year from age(now(), joined_on)) + 1)
* '1 year'::interval
)::date as next_anniversary,
(joined_on +
(extract(year from age(now(), joined_on)) + 1)
* '1 year'::interval)::date - now()::date
as days_remaining
from users
order by days_remaining asc;
Notice that some of the sub-expressions are repeated over and over again: we can
polish it up by using a lateral join to abstract out the years_active
expression:
select
user_id,
name,
joined_on,
years_active,
(joined_on + (years_active + 1) * '1 year'::interval)::date as next_anniversary,
(joined_on + (years_active + 1) * '1 year'::interval)::date - now()::date
as days_remaining
from users,
lateral (
select extract (year from age(now(), joined_on)) as years_active
) as e1
order by days_remaining asc;
We can polish it up further by using yet another lateral join:
select
user_id,
name,
joined_on,
years_active,
next_anniversary,
next_anniversary - now()::date as days_remaining
from users,
lateral (
select extract (year from age(now(), joined_on)) as years_active
) as e1,
lateral (
select (joined_on + (years_active + 1) * '1 year'::interval)::date as next_anniversary
) as e2
order by days_remaining asc;
Here are some links and posts for further reading:
Links/Acknowledgment #
- PostgreSQL Documentation - SQL Commands - SELECT,TABLE,WITH
- PostgreSQL Documentation - Table Expressions
- PostgreSQL Documentation - Query Language (SQL) Functions
- Dan Robinson - Heap - PostgreSQL’s Powerful New Join Type: Lateral
- StackOverflow - What is the difference between a LATERAL JOIN and a subquery in PostgreSQL
- PopSQL - How to Use Lateral Joins in PostgreSQL
- Steve Pousty - CrunchyData - Iterators in PostgreSQL with Lateral Joins
- lukaseder - jooq - Add LATERAL Joins or CROSS APPLY to Your SQL Tool Chain